![]()
Chad Sakac over at http://virtualgeek.typepad.com already blogged about the APD bug in December last year. You can find his post here.
Just a short quote from Chad his post about the symptoms of this APD bug:
Recently saw a little uptick (still a small number) in customers running into a specific issue – and I wanted to share the symptom and resolution. Common behavior:
- They want to remove a LUN from a vSphere 4 cluster
- They move or Storage vMotion the VMs off the datastore who is being removed (otherwise, the VMs would hard crash if you just yank out the datastore)
- After removing the LUN, VMs on OTHER datastores would become unavailable (not crashing, but becoming periodically unavailable on the network)
- the ESX logs would show a series of errors starting with “NMP”
Examples of the error messages include:
“NMP: nmp_DeviceAttemptFailover: Retry world failover device "naa._______________" – failed to issue command due to Not found (APD)”
“NMP: nmp_DeviceUpdatePathStates: Activated path "NULL" for NMP device "naa.__________________".
What a weird one… I also found that this was affecting multiple storage vendors (suggesting an ESX-side issue). You can see the VMTN thread on this here.
We found out about this issue during a big storage project. We where creating a lot of new LUNs and where removing a lot of the old LUNs. If you remove a LUN on a way not mentioned in Chad his post:
This workaround falls under “operational excellence”. The sequence of operations here is important – the issue only occurs if the LUN is removed while the datastore and disk device are expected by the ESX host. The correct sequence for removing a LUN backing a datastore.
- In the vSphere client, vacate the VMs from the datastore being removed (migrate or Storage vMotion)
- In the vSphere client, remove the Datastore
- In the vSphere client, remove the storage device
- Only then, in your array management tool remove the LUN from the host.
- In the vSphere client, rescan the bus.
So when we used the workaround described above, everything went fine. But at my current employer, we use a large LeftHand iSCSI SAN. One of the great things of Lefthand SAN is the ability to move LUNs between different clusters. With the APD bug, we couldn’t use this option anymore.
When we discovered this APD bug we contacted VMware Support. After a couple of weeks we received an e-mail with the following fix.
I can now confirm that the APD (All paths dead) issue has been resolved by a patch released as part of P03.
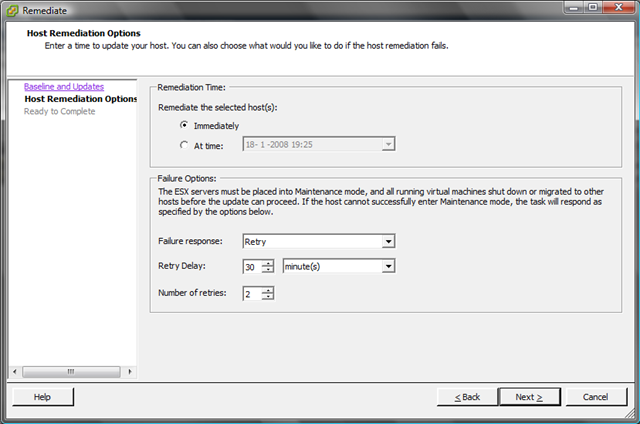
To install this patch, please upgrade your hosts to vSphere Update 1 and use Update Manager to install the latest patches.
Please ensure that ESX400-200912401-BG is installed as this resolves the APD problem
We upgraded one of our clusters to Update 1 and installed the latest patches including the ESX400-200912401-BG patch. After installing the patch, we did some tests and I can confirm that the APD bug is history!!
To reproduce this issue I created two iSCSI LUNs on the EMC VSA. Instead of removing the LUNs I disconnected the iSCSI network to simulate this. So before I disconnected the iSCSI network, all LUNs are working just fine:

After I disconnected the iSCSI network and waited a while, all the paths to the EMC LUNs are dead and they are colored red:

This is just normal behavior but before installing the ESX400-200912401-BG patch, the ESX host will stall for 30 till 60 seconds. This means that all the VMs running on a host of which a LUN was disconnected will stall, even though the VM is on a different datastore!! I am happy that VMware has solved this APD bug.
If you want to make sure if you already installed the APD patch, you can easily verify this with the vCenter Update Manager.
Go to the tab Update Manager and open the Admin View. Add a new baseline. Select the Host Patch option:

In the next screen select Fixed:

Now we are going to create a filter. Enter the name of the patch:

Select the ESX400-200912401-BG patch:

When the new baseline is ready, return to the Compliance view and attach the new baseline:

The final step is to perform a scan on your Datacenter, Cluster or ESX Host. Now wait and see if the patch is already installed or not.
More info about the patch can be found here:
For the readers who cannot upgrade to vSphere Update 1 and the latest patches, you can find some workarounds here: